
I Stopped Self-Managing Infrastructure
This past Black Friday 2025 was the most relaxed one I've had in years. I knew the setup was solid. Several clients had planned flash sales and promotions, nothing unusual for the season. I checked in a few times, looked at the dashboards, and that was it.
One client launched a flash sale that nobody expected to take off the way it did. 3.2 million requests in 60 minutes! That's roughly 900 requests per second, sustained, for an hour.
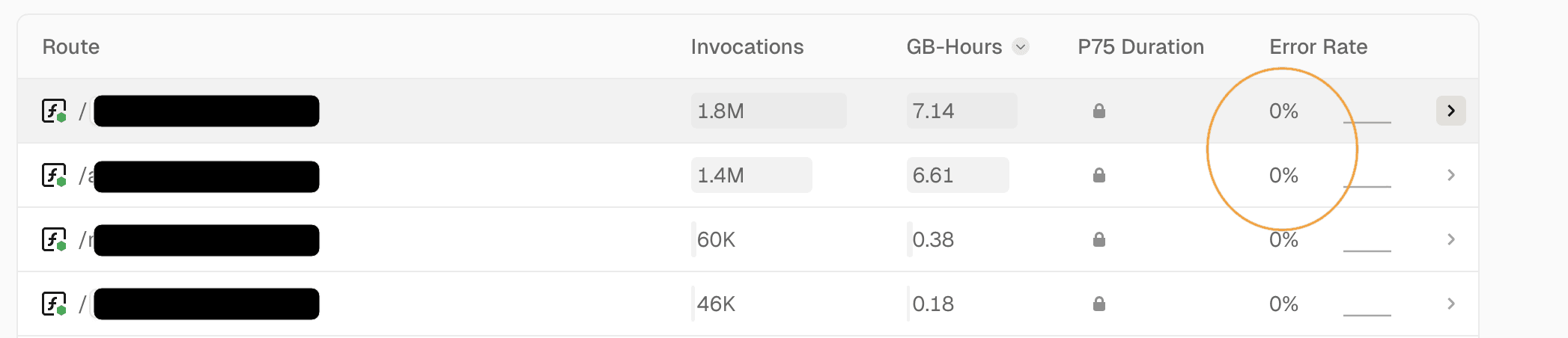
I checked the dashboard: 0% error rate across all 3.2 million requests. Zero! Vercel's edge network scaled automatically, the CDN handled static assets, ISR served cached pages. No manual intervention. No engineer on call. No "let's spin up more pods" panic.
The infrastructure cost for that hour: roughly $18.
The efficiency argument
I've worked on projects where self-managed Kubernetes was the infrastructure choice. It works, I'm not going to pretend it doesn't. I remember enjoying setting up Linux servers with nginx myself back in the day. But the overhead is real, and it compounds in ways that aren't obvious until you're deep in it.
You need a DevOps engineer (or a team) to maintain the cluster. That's salary, on-call rotations, and context-switching every time something needs scaling, patching, or debugging. Deployments take longer because they go through infrastructure pipelines that weren't designed for frontend iteration speed. I haven't worked for a single German client in all these years that did not have a code freeze around Black Friday. Deploy pipelines running 20 minutes are real. Instant rollbacks? Not in place. So the team that's supposed to move fast is frozen in place for the most critical sales period of the year.
The math on self-hosted infrastructure for a comparable Black Friday spike: baseline server costs running 24/7, DevOps salary, on-call charges, and the over-provisioning you need to handle unexpected peaks.
$18 vs. that.
DevOps as bottleneck
This isn't an argument against DevOps engineers. They're skilled people solving real problems. It's an argument against making DevOps a dependency in your deployment pipeline when you don't have to.
I have seen it in scale-up teams: the DevOps engineer becomes the bottleneck not for deployments themselves, but for everything around them. Monitoring, scaling pods, debugging cluster issues, managing certificates. When traffic spikes, someone has to be watching dashboards and manually adjusting capacity. The team that's supposed to move fast is dependent on infrastructure decisions that have nothing to do with their code.
Managed platforms like Vercel remove that dependency. The frontend team deploys by pushing to git. Preview environments spin up automatically. Scaling is the platform's problem. The DevOps work doesn't disappear, it just moves to where it belongs: the platform provider who does it at scale for thousands of projects, not your one team doing it for one project.
What actually handled the traffic
For context on what made that Black Friday work without intervention:
Edge network: requests get served from the node closest to the user. No single origin server bottleneck. When traffic spikes, the edge network absorbs it across hundreds of locations.
ISR (Incremental Static Regeneration): product pages were pre-rendered and cached at the edge. When a user hits a product page, they get the cached version instantly. The page revalidates in the background on a set interval, so content stays fresh without rebuilding the entire site.
CDN for static assets: images, scripts, stylesheets served from cache. These never hit the origin server during the flash sale.
The combination meant that the vast majority of those 3.2 million requests never reached the application server at all. They were served from cache, at the edge, in milliseconds.
The real cost comparison
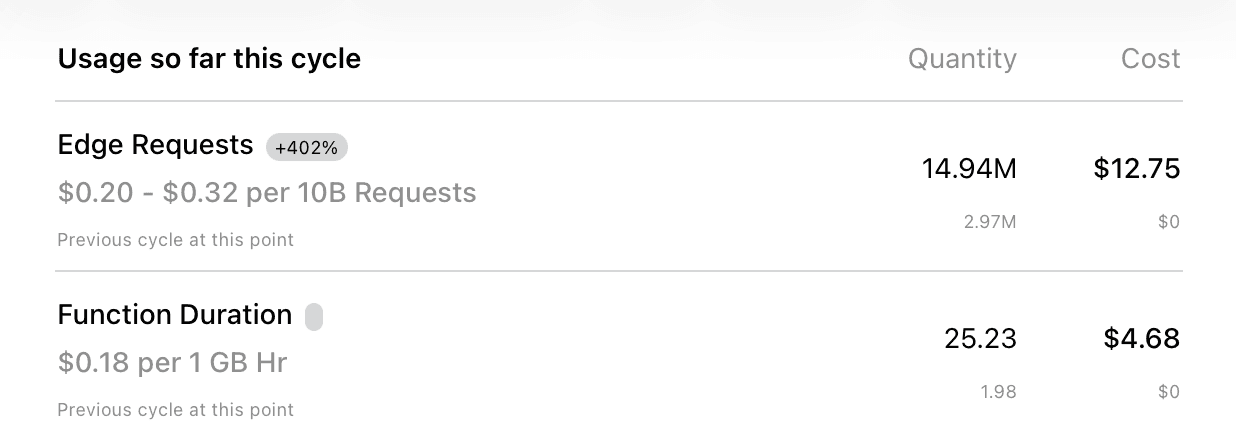
Let me put the $18 in context. The additional infrastructure cost for handling that Black Friday 2025 spike:
| Resource | Usage | Cost |
|---|---|---|
| Edge Requests | 14.94M | $12.75 |
| Function Duration | 25.23 GB-Hours | $4.68 |
| Total | $17.43 |
That's the additional cost on top of the base plan. The flash sale generated a massive spike, and the additional charges for absorbing it were $18.
A comparable self-managed setup for a traffic-heavy e-commerce site would require provisioning for peak capacity. You'd need load balancers, auto-scaling groups (which still need configuration and monitoring), CDN configuration, SSL management, and someone to maintain all of it. The baseline cost alone, before any traffic hits, would exceed what the entire month cost on Vercel.
I'm not saying managed platforms are the right choice for every project. If you're running ML workloads, processing video, or need specific compliance requirements that demand infrastructure control, self-managing makes sense. For a Next.js e-commerce frontend serving cached pages and handling flash sales? The decision is clear.
I stopped self-managing infrastructure because the trade-off stopped making sense. The time my clients' teams used to spend on infrastructure now goes into building features. And on Black Friday, the only thing anyone had to monitor was the sales dashboard.